| Introduction to info, man and the whatis database | ||
|---|---|---|

|
Chapter 1. Tour de Shell Scripting |  |
| Introduction to info, man and the whatis database | ||
|---|---|---|
|
|
Chapter 1. Tour de Shell Scripting | |
This is a shell scripting course, but we're going to start off by looking at the info pages, the man pages and the whatis database before we start scripting. This is a good idea because at least we know that we're all on the same page.
So, what is this man page, and info page, and that other stuff you mentioned?
Man pages is a term used as a short-hand for manual pages - or the manual. Info pages, are like manual pages (man), but are a newer format that the movers and shakers are trying to adopt.
Which to use? Well both actually.
In some cases, man does not contain all the necessary information, and then one needs to refer to the info pages. Sometimes it may be far easier to locate that which you are looking for by firing up the manual page. First we'll tackle info pages.
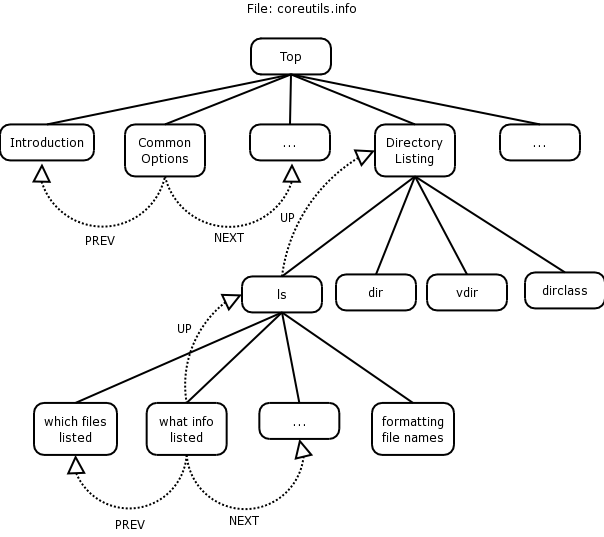
The diagram below illustrates the structure of the info pages. Refer to it while reading this section
Info pages are like man pages in many ways, except they provide a lot more information than man pages (well mostly anyway). Info pages are available on all the Linux distributions currently available, and they are similar to the man pages, although in some instances give you more information.
If we look at a typical way of invoking info, it would be the word info, followed by a space, followed by the name of the command that you want to invoke info on. For example, for the command ls:
info ls
---^-
|
![[Note]](../images/admon/note.png) |
Note |
|---|---|
|
Type the commands just as you see them here. I have placed minus signs under the command and it's arguments, and a caret (^) under the space. This is to illustrate that the command should be typed EXACTLY as is. |
|
This should give us an information page on the ls command. We could invoke info on a whole range of utilities by typing:
info coreutils
---^------
|
where coreutils is just another group of info pages. Coreutils is a grouping of info pages, containing commands such as ls, cd, cp, mv or list directory contents (ls), change directory (cd), copy files and directories (cp) and move or rename files (mv). One could, for instance, type:
info mv
|
The way info is structured, is that when you first start it, it will display the node at which you are beginning your search.
In our coreutils example, on the top of the page (right at the top) the first line looks as follows:
File: coreutils.info, Node: Top, Next: Introduction, Up: (dir)
|
Starting on the left-hand side, we see the file that we're "info'ing" the coreutils.info file.
The filename that contains information about the ls, cp, mv and cd commands amongst others is coreutils.info.
The current Node is Top, which indicates that we're at the top of the coreutils info page and cannot go higher within this group of pages.
From the top level of the info page on coreutils we can now do a couple of things:
We can go to the next node (by typing 'n'), which is the next topic, called Introduction. You will notice that there is no link to a Previous topic, since we are at the top of this group of pages.
We could scroll down to the menu and select a particular topic (node) we want displayed.
File: info.info, Node: Top, Next: Getting Started, Up: (dir)
Info: An Introduction
*********************
The GNU Project distributes most of its on-line manuals in the "Info
format", which you read using an "Info reader". You are probably using
an Info reader to read this now.
If you are new to the Info reader and want to learn how to use it,
type the command `h' now. It brings you to a programmed instruction
sequence.
To read about expert-level Info commands, type `n' twice. This
brings you to `Info for Experts', skipping over the `Getting Started'
chapter.
* Menu:
* Getting Started:: Getting started using an Info reader.
* Expert Info:: Info commands for experts.
* Creating an Info File:: How to make your own Info file.
* Index:: An index of topics, commands, and variables.
--zz-Info: (info.info.gz)Top, 24 lines --All-------------------------------------------------------------------------
|
If you were to scroll down to the Directory listing line, you'll see that on the left-hand side there's an asterisk, followed by the topic, followed by a double colon and what is inside the info group:
* Directory listing:: ls dir vdir d v dircolors
|
These are the topics covered in this particular node.
If you hit enter at this stage. You should see that the node has changed. The top line of your page will look as follows:
File: coreutils.info, Node: Directory listing, Next: Basic operations,Prev: Operating on characters, Up: Top
|
This is similar to the top of the coreutils.info page as described above, but this example includes a previous node, which is "Operating on characters", with the next node being "Basic operations".
Once I've scrolled down (using my arrow keys) to * Directory listing, I may want to go and look at information about the ls command to see what I can do with ls. Again you use the up or down arrow key and scroll to "ls invocation" and hit Enter
Once there you can read the ls info page to see what it tells you about the ls command.
How do you go back to the Directory listing info page? Type u for UP, which should take you to the previous listing.
How do you go from "Directory listing" to "Basic operations", when you're currently at the "Directory listing" node? n will take you to the NEXT node (taking you from the "Directory listing" to "Basic operations").
If you want to go right to the top, in other words, back to the coreutils group, press t for TOP.
You can do searches within info by using the forward slash (/) and then include a pattern, which might be something like
/Directory
|
This tells info that you want to look for the pattern Directory. Bingo! We find Directory listing, as it is the first entry that matches the pattern. If you want to use the same pattern to search again, press forward slash followed by enter:
/<ENTER>
|
This will allow you to search for the pattern "Directory" once again. How do you quit info? q will quit info.
If you want to go one page up at a time, then your backspace key will take you one page up at a time.
Finally, to obtain help within info, type '?'. This will get you into the help page for info. To leave help, press CTRL-x-0.
That is essentially how info works. Part of the reason for moving to info rather than man pages is to put everything into texinfo format rather than gz-man format. In the future, much more software will include manual pages in texinfo format, so it's a good idea to learn how the info pages work.
Run info on find.
press u.To which node of the info page does this take you?
Search for the find command.
Select the find command.
If I were to try to find a file using it's inode number, how would I do this. (Hint: search for inum)
What node does this (inum) form part of?
Go to the "Finding Files" node and select the Actions node.
How do you run a command on a single file once the file has been found.
Having covered the info pages, we need to look at man pages since man is the standard on most UNIX and Linux systems. 'man' is short for manual. This is not a sexist operating system. There are no woman pages but we can find out how to make some a little later (to keep man company).} Manual pages are available on every operating system. (If your system administrator hasn't installed them, ask him politely to do so, as no Linux system should be running without man pages.).
The man command is actually run through a program called less, which is like more except it offers more than the more command does.
|
Note |
|---|---|
|
Mark Nudelman, the developer of less, couldn't call it more, since there was already a more command, so it became less. Linux people do have a sense of humor. |
|
To invoke man pages type:
man <command>
|
For example, the ls command that we info'ed above,
$ man ls | less
|
Looking at our example above, the manual page on the ls command is run through the less command.
What can you do from within man?
Well, pretty much the things you can do with info. Instead of a menu system, and nodes, we're looking at a single page detailing all the options and switches of the ls command.
If we want to search for a particular pattern we would use forward slash (/) just like we did in info.
For example, we could type
/SEE ALSO
|
This pattern search would take us to the end of the man page to look at the SEE ALSO section.
We could type question mark with a pattern, which does a reverse search for the specified pattern. Remember forward slash does a forward search and question mark does a reverse search.
?NAME
|
This pattern search will reverse search up the man page to look for the pattern NAME.
|
Note |
|---|---|
|
You will notice that I'm not saying look for the string NAME, rather I'm saying look for the pattern NAME. This is because pattern matching is a critically important part of UNIX and Linux and shell scripting. We'll learn more about patterns as we go through the course. |
|
If we want to scroll down one page at a time within the man page (i.e. we've looked at page 1 and we've read and understood it, and we want to go to page 2), then the space bar takes us forward by a page.
Similarly if we want to reverse up the man page, we press b for back, which will scroll backwards through the man page.
How do we get back to our prompt? The 'q' key comes in handy again. 'q' for quit.
man pages are generally broken down into a host of different sections. There's a SYNOPSIS section, a DESCRIPTION section, and a SEE ALSO section. Read through the man page and you will understand the different sections.
If you need help on moving around through the man page, type 'h' for help, which will give you a listing of all the help commands. You will see that it has displayed the help commands NOT for man but for less. Why? Because the pager for man, (pager, the tool that gives you one page at a time instead of just scrolling the man page past you too fast to read), is the less command
We will cover the less command a bit later but you can look it up with the info pages as follows:
info less
|
So 'h' within the man page will show you help on the 'less' command at the same time as displaying the requested manual page.
Sometimes you need to read a man page three or four times before you completely understand it, and of course sometimes you may never understand it! Don't be deterred. That's what separates the kanga's from the roo's.
do a man on the nl command
What is the function of this command?
How would one right justify the number ensuring it has leading zeros?
And also number non-blank lines?
Who wrote this program?
What else should we view to get a complete picture of the nl command?
What version of the nl command do you have installed on your system?
The whatis database is usually rebuilt on a Linux system at night. The job of the whatis database is to search through every manual page on your system looking for the NAME section within these man pages, classifying them and placing them into a database, to facilitate searching in the future.
The whatis database is useful in that it gives us the ability to quickly look up what a particular command does. So if I asked you to tell me what the nl command does, you could look it up in the man pages or you could look it up in the whatis database.
man nl
|
or
whatis nl
|
The latter method should return with the NAME section from the man page, showing you what the commands job is on the system. It should tell you that nl numbers the lines. Similarly wc counts words, lines and characters for you.
The whatis database is very useful because it allows you to quickly find out, what a particular command on the system does.
If the whatis database is not up-to-date, it is quite simple to update it. Generally though, the updating of the whatis database is a simple automated process. Once a night, the operating system should go about updating the whatis database. Even if the system administrator has installed a whole host of new software on the system, by virtue of the fact that the man pages for that software would be installed at the same time as your new application is installed, your whatis database should pick up those pages and add them to its database each night.
As a side note, updating the whatis database manually is simply a matter of
$ makewhatis -u -w
|
and the whatis database will be updated.
The idea behind being lazy is that you want to take a system and get it to do stuff automatically for you, so that you can spend more time surf-skiing or walking on the mountain, or doing things you enjoy doing.
Now people say to me "Why must I be lazy?"
Because it means that you need to think of better, quicker ways of doing things and shell scripting is a way to achieve that.
If you haven't thought of a better way of doing it, you're not applying your mind. If you apply your mind you will find that there are many different ways to skin a cat in Linux. Shell scripting is one of the many ways you can speed up mundane tasks.
So the idea behind shell scripting is to automate this process of getting jobs to be done on your behalf.
To achieve this using scripts, you could take a series of system administration tasks, put them together in a single script, run them unattended and they should produce output that would (hopefully) match what you require.
Finally, this brings me to another adage.
There is never only one way of solving a problem in Linux. The way I solve a problem may be completely different to the way you solve it. But does this matter? Absolutely not! Is my solution better than yours? Perhaps, but I have been doing this for a long time, so take note of how I do it.
|
|
 |
|
| Chapter 1. Tour de Shell Scripting |  |
Revising some Basic Commands |