| Files and Directories | ||
|---|---|---|

|
Chapter 4. Essentials |  |
| Files and Directories | ||
|---|---|---|
|
|
Chapter 4. Essentials | |
Each disk drive in a Unix or Unix-like system can contain one or more file systems. A file system consists of a number of cylinder groups, which in turn contain inodes and data blocks.
Each file system has its characteristics described by its "super-block", which in turn describes the cylinder groups. A copy of the super-block is made in each cylinder group, to protect against losing it.
A file is uniquely identified by its inode on the filesystem where it resides.
A data block is simply a set block of space on the disk in which the actual contents of files are stored; often more than one block is used to hold the data for a file.
An inode is a data structure which holds information, or metadata, about a file on that filesystem.
You can use "ls" with the "-i" option to find a file's inode number:
student@debian:~/dataset$ ls -i 6553 one.txt 7427 two.txt |
An inode itself contains the following information:
the device where the inode resides
locking information
the addresses of the file's data blocks on disk (NOT the data blocks themselves)
Let's look at the directory listing below:
student@debian:~/dataset$ cd .. student@debian:~$ ls -ila total 8 4944 drwxr-xr-x 4 student student 1024 Feb 19 03:45 . 4943 drwxrwsr-x 3 root staff 1024 Jan 29 22:32 .. 5665 -rw------- 1 student student 658 Feb 19 03:22 .bash_history 4946 -rw-r--r-- 1 student student 509 Jan 25 12:27 .bash_profile 6540 -rw-r--r-- 1 student student 1093 Jan 25 12:27 .bashrc 6540 drwxr-xr-x 2 student student 1024 Feb 19 03:45 dataset 7425 drwxr-xr-x 2 student student 1024 Feb 19 03:45 dataset |
The first line displayed is the total number of 512-byte blocks consumed by the files in the directory displayed.
As you can see from the remaining output, a file has several attributes, or metadata, associated with it. This data is stored in the inode and is, in field order:
This is a ten character string which determines who is allowed access to the file. The string is composed of a single initial character, which determines the file type and a permission field.
The following are the list of file types, and their associated character:
- regular file
d directory
b block device
c character device
l symbolic link
s socket link, also called a Unix networking socket
p first-in first-out (FIFO) buffer, also called a named pipe
A regular file is the most common one that you will have to deal with; plain text files, configuration files, databases, archives, executables and even the kernel are all regular files.
A directory is a file, which contains zero or more other files names and their associated inode numbers.
You should only find character and block device files in your "/dev" directory. These files are used to allow communication between "userland" programs and the kernel. Character devices transfer data a single character at a time (eg, console, printer), while block devices transfer data in fixed-size chunks (eg, harddrive).
A symbolic link is a pointer to another file, and is therefore useful for creating shortcuts or aliases to files and directories.
A socket link file allows for two or more programs to communicate with each other. A common example of this is the system logging daemon (syslogd), which other programs communicate with via the "/dev/log" file. The logging deamon reads information out of the socket file, while other applications send information to it.
student@debian:~$ ls -l /dev/log
srw-rw-rw- 1 root root 0 Feb 25 11:03 /dev/log
|
A FIFO buffer is a file whose contents are read out in the order that they were written to the file.
A semaphore file, in Linux programming parlance, is simply a file used for two or more Linux processes to communicate with each other; also known as Inter-Process Communication, or IPC for short.
The simplest sort of semaphore is a binary one; in other words, it is either "on" (set to "1") or "off" (set to "0"). The semaphore file can be read and written to, this is based on its permissions, by the processes that wish to communicate with each other.
An example might be a database application, which will only make a copy of the database when the semaphore is set to "off", indicating that the database is not currently in use.
The 9 characters that follow the file type character are in fact three triplets, which affect who can do what with the file. The triplets are the permissions which affect: the file owner, the file group and everyone else.
The three possible permissions are, in order:
Table 4.2. File Permissions Table
| r | read access | OR | - | not readable |
| w | write access | OR | - | not writeable |
| x | execute access | OR | - | not executable |
The absence of a permission bit is indicated with a dash ("-").
The read and write permissions are self-explanatory for both the regular and directory files.
If the execute permission is set on a regular file, it means that the file can be executed; in other words, it's an application or program that may be run on the system.
If the execute permission is set on a directory, it means that the directory can be accessed (eg, using the "cd" command).
For more information on file permissions, see the section on "chmod" below.
This is the number of links (see hard links below) that currently point to the file; when this number reaches zero, the filesystem makes the blocks containing the file contents available for use again. The most common scenario where this occurs is when the file is deleted.
The person who owns the file. This information is stored as a numeric value on the filesystem, but is then looked up by tools such as "ls" from the /etc/passwd file, or equivalent file.
The group whom owns the file. This information is stored as a numeric value on the filesystem, but is then looked up by tools such as "ls" from the /etc/group file, or equivalent information source.
A Unix group may contain none, one or more users, who will then be able to access the files and directories owned by that group, based on that groups permissions as discussed above. This is useful for sharing files between two people, as a file can only have one owner.
The abbreviated Month Name, Day Of The Month, Hour and Minute the file was last modified.
If the modification time of the file is more than 6 months in the past or future, then the year of the last modification is displayed in place of the hour and minute fields.
The File name is not stored in the inode!
File names under Linux are case-sensitive. They are limited to 255 characters in length and can contain uppercase, lowercase, numeric characters as well as escape characters.
Although it's a good idea to keep them generally all in lowercase avoiding use of escape characters where possible, so that the file names are easier for you to deal with in the shell.
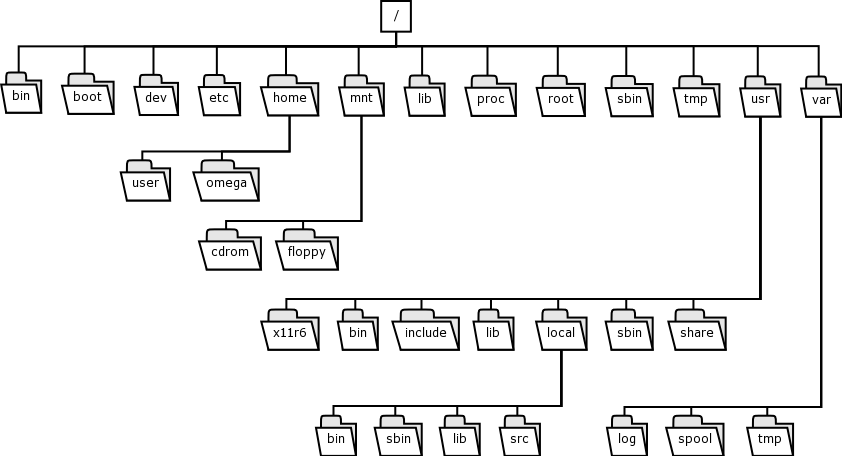
The filename is held in the directory listing and referenced by the inode number. Look at the following diagram this should make it clearer.
The Linux filesystem is broken up into a hierarchy similar to the one depicted below, of course you may not see this entire structure if you are working with the simulated Linux environment:
The "/" directory is known as the root of the filesystem, or the root directory (not to be confused with the root user though).
The "/boot" directory contains all the files that Linux requires in order to bootstrap the system; this is typically just the Linux kernel and its associated driver modules.
The "/dev" directory contains all the device file nodes that the kernel and system would make use of.
The "/bin", "/sbin" and "/lib" directories contain critical binary (executable) files which are necessary to boot the system up into a usable state, as well as utilities to help repair the system should there be a problem.
The "/bin" directory contains user utilities which are fundamental to both single-user and multi-user environments. The "/sbin" directory contains system utilities.
The "/usr" directory was historically used to store "user" files, but its use has changed in time and is now used to store files which are used during everyday running of the machine, but which are not critical to booting the machine up. These utilities are similarly broken up into "/usr/sbin" for system utilities, and "/usr/bin" for normal user applications.
The "/etc" directory contains almost all of the system configuration files. This is probably the most important directory on the system; after an installation the default system configuration files are the ones that will be modified once you start setting up the system to suit your requirements.
The "/home" directory contains all the users data files.
The "/var" directory contains the user files that are continually changing.
The /usr directory contains the static user files.
The filesystem layout is documented in the Debian distribution in the hier(7) man page.
Read the file system hierarchy man page. Can you find the directory where this particular man page file itself resides?
One of the benefits of having a /var directory which contains all the files that are changing or which are variable, and having another directory called /usr where the files are static and they are only read, would be that if you wanted to create an incredibly secure system you could in fact mount your /usr directory read-only.
This would mean that even while the OS system is up and running, no one, not even the root user is allowed to modify any files in that directory.
However, because the system needs to be able to have read and write access to certain files in order to function, the /var partition would serve this purpose exclusively, allowing you to mount /usr as read-only.
So this means that you will be able to have a fully running machine doing all the things you would normally do except it will be virtually impossible for anybody to be able to place any Trojans or any other malicious binaries in your /usr directory.
Another benefit is that you can run diskless or almost diskless clients. Your /usr directory could for instance be mounted over the network from another machine. This means that you don't have to sacrifice all the disk space and instead you could rely on the network to provide your system with the needed binaries. This used to be very popular 5-10 years ago when disk space was quite a lot more expensive than it is today.
However thin-client technology, that seems to be making a comeback, could benefit quite a lot with being able to mount large applications from a remote file system that has a large amount of space, and the thin client could have no or very little disk space available. Examples of large applications are Open Office and Mozilla.
The editor we will be using is a text editor called "vim". Back in the days when Unix was growing up, people didn't even have a visual console to be able to see what was going on when they were running commands or editing files. They would use tele-type terminals.
The command that they used to edit files, was ed. ed is a very unfriendly editor, it is not as interactive as you would be used to using in most modern editors.
The "ed" application would simply give you a prompt and then you would have to tell ed, which line you want displayed. It would then display that line to you, that line only - you wouldn't be able to get an overall feel of what the text file looked like that you were editing.
If you wanted to insert a line, then you would tell ed that you wanted to insert a line at a particular position and then pipe the line that you wanted to insert and it would then insert it for you.
If you wanted to remove a word or delete a line, you would have to specify the location of the word or line respectively.
Obviously this is fine if you know the file or it is very short but if it's a large file or it's new to you then you're going to spend a long time in order to make any modifications to it.
Some time after this it became possible to get video display units, or visual consoles, which had the ability allow users to view more than a single line at a time. Around this time, "ed" developed into "ex", which was a more powerful version of the editor, but still limited to working on a single line at a time.
Unfortunately, these consoles were initially very slow, so screen output was still limited to the bare minimum.
Time progressed, and displays become faster; in fact, fast enough to be able to display an entire 25 lines without too much effort; and here we enter the era of the visual editor, also known as "vi".
Vi has 3 modes of operation: visual mode, insert/editing mode and an ex mode (where you actually access the original command line ed editor).
Those of you who have had to use edlin in DOS before will probably be able to relate to ex.
Under Linux, there is no vi, there is vi improved, or vim. vim is compatible with vi in almost all respects and has a vi compatibility mode available to complete the compatibility in any other respects. However vim expands greatly on the features of vi and allows you to do extra things such as Syntax highlighting, better integration with various other software packages. The ability to perform scripting functions on your documents, etc.
To start up vim, just type "vi", followed by the name of the file you want to edit.
![[Note]](../images/admon/note.png) |
Note |
|---|---|
|
On Debian systems you have the option of having both an open source version of vi (called nvi) and vim installed at the same time. |
|
Debian will actually call "vim" when you execute the "vi" command if "vim" is installed, otherwise it will load "nvi".
student@debian:~$ cd dataset/ student@debian:~/dataset$ vi one.txt_ |
In the example above, we're opening the file "one.txt" for editing.
You may find the keys for vim to be tricky to learn, but, once mastered, they allow you to edit documents and configuration files with the minimum number of keystrokes, and with great speed.
Initially, vim will start in "visual mode". Once open the screen will be blank and probably have tildes running down the left hand side of the page indicating un-used lines.
In this mode you can use the "h", "j", "k", and "l" keys to perform your movement functions.
vim also allows you to use the cursor keys, so if you find the so-called VI movement keys daunting you can make use of these instead.
To switch to "insert mode", press the "i" key, notice that the letter "i" does not print on the screen - but now if you start typing your text will be shown on the screen.
This will tell vim that you want to start inserting text at the current cursor position in the file that you are editing. You can tell when you are in insert mode as vim will display the word "INSERT" in the bottom left of the screen.
By pressing "i" you will enter insert mode, text will be inserted to the right of the current position of the cursor. To insert from the beginning of the line and get into insert mode at the same time, press "I" (shift + "i").
To insert text in the line above the cursor, press "O" (shift + "o"). To insert in the line below the cursor, press "o" . To append text just after the current position of the cursor press "a", to append text at the end of the currentl line, press "A" (shift + "a").
The figure below demonstrates how this affects the place where you will insert text. The first one indicates the position of the cursor, before entering into insert mode in these examples.
Figure 4.6. Different ways of getting into Insert Mode, and how that effects the place where text is inserted.
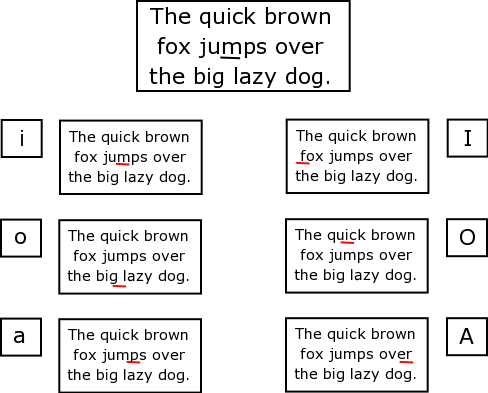
When you want to return to visual mode, press the "escape key" (Esc) on the keyboard. The word INSERT will disappear from the bottom of your screen.
You can delete characters while in visual mode by hitting the "x" key; this will delete the character currently above the cursor. (A capital "X" will work as a backspace key does deleting one character and moving backwards to the next character.)
The shortcut to delete a line is "dd"; hit the "d" twice in quick succession. (You can use "p" to paste the line afterwards). To delete two lines you would use the command "2dd".
If you wish to join the line below your current line to the end of the current line use "J" (that's a capital).
To insert a line below the one you are currently editing, you can press "o"; this will also place you in insert mode on the newly created line. (Capital "O" will open a line above your current line and also put you into INSERT mode.)
To tell vim that you wish to save and exit, press "ZZ" (two capital "Z"'s in quick succession).
You can enter ex mode, which allows you to work as if you were in the "ex" editor, by hitting the ":" key when in visual mode. A colon will be printed at the base of the screen waiting for an ex command. To get back to your text press the escape key (Esc).
While in "ex" mode try some of the following suggestions:
To access vim's built in help system, type "help" at the ex prompt (:) and ENTER.
You can perform a search an replace in ex mode by using the following Syntax: %s/search/replace/g
Try the example above in the sample text window, search globally for the occurrence(s) of "now" and change that to "not".
You can also save ":w" and quit ":q" or save & quit in one command using ":wq" from vim while in ex mode. If you do this point remember to re-enter vim afterwards.
To recap there are three modes of operation:
Command mode
Allows positioning and editing commands to perform functions. Entered via (Esc), from entry mode, or when you return from Last-line mode
Entry mode
Allows you to enter text. Enter this mode via typing; A i I o O c C s S or R from command mode.
Last-line mode
Initiated from command mode by entering advanced editing commands like : (a colon), / (a forward slash), ? (a question mark) and ! (a bang or exclamation mark).
Syntax: vi <filename> |
Linux filesystems are case sensitive, and support the full range of high and low ASCII characters; this makes it very powerful.
However, humans can only easily deal with a small number of this range of characters. For this reason, it's a good idea to keep the names of your files all lowercase, and to avoid spaces, brackets or any other "special" characters.
Important files, like "README" may be named with all capitals, so that they stand out better in a listing.
The "/" character is special in that it is used to denote a directory structure.
Unlike DOS or Windows, Linux has no strict concept of having file "extensions" and thus does not use them to determine what sorts of file it is. There is no "ls.exe", instead it's just "ls".
However, there is nothing to stop you creating a "readme.txt" file with a .txt extension; Linux just treats the period (".") as part of the filename instead of a special character. Indeed, you can have multiple periods; for example "backup.tar.gz".
So, let us go over the rules in a summary:
Linux is case sensitive.
We would advise that you use the lower-case alpha characters (a to z) and the numeric characters 0 to 9 when you name a file.
A (.) in front of a filename means that it is a hidden file, whereas a (.) anywhere else in the filename is treated as a normal character by Linux.
There are certain characters that will be interpreted by the shell and have a special function within the shell - do not use these in a filename. Some of these characters are:
; | < > lefttick " righttick $ ! % ( ) ^ \ [ ] & ? #
Don't use control characters such as ^G (bell) or ^d (interrupt character), the space bar, the tab or the backspace. These all have special meaning to the shell.
Observe the rules for the length of your filenames.
So how can you tell what sort of file a file is without actually looking inside if it doesn't have a handy extension?
The file command examines the contents of the file, and then compares it against a "magic" filter file, which tells the "file" command what sort of patterns would exist in what sort of file.
This is a powerful command, give it a try:
student@debian:~$ file /bin/ls /bin/ls: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), dynamically linked (uses shared libs), stripped student@debian:~$ file dataset dataset: directory student@debian:~$ file dataset/one.txt dataset/one.txt: ASCII English text student@debian:~$ file /etc/init.d/rc /etc/init.d/rc: Bourne shell script text executable |
Syntax:
file <file>
|
Use the file command on some of the files in the /dev directory.
There are several command line tools available for manipulating files in a Linux environment:
This command can be used to create an empty file, or update the modification time of an already existing file.
student@debian:~$ cd dataset/
student@debian:~/dataset$ ls
one.txt two.txt
student@debian:~/dataset$ touch testing
student@debian:~/dataset$ ls
one.txt testing two.txt
student@debian:~/dataset$ _
|
Syntax:
touch <filename>
|
Try using touch to update the modification time of an existing file. What command can you use to check that the time has in fact been changed?
You can use the "mv" (move) command to move a file into another directory, or to change its name:
student@debian:~/dataset$ ls -i 6553 one.txt 7437 testing 7427 two.txt student@debian:~/dataset$ mv testing testing.123 student@debian:~/dataset$ ls -i 6553 one.txt 7437 testing.123 7427 two.txt student@debian:~/dataset$ _ |
Check the inode of the file above that you have just moved - what do you notice?
You should notice that the inode remains the same, therefore the only thin that has changed is the filename, which is held in the directory listing. Remember that the filename is ONLY held in the directory listing and not by the inode.
The mv, cp and rm commands all accept a "-i" switch. This makes the command "interactive", which means that the command will ask you to confirm an operation if it is a potentionally destructive one. For example, if you copy one file over another, or try to delete a file.
Syntax:
mv [-i] <oldfilename> <newfilename>
mv [-i] <filename> <directory>
|
You can use the "cp" (copy) command to make a copy of a file - in other words to make an identical copy of the datablocks but at another address, using a different inode number:
student@debian:~/dataset$ ls -i
6553 one.txt 7437 testing.123 7427 two.txt
student@debian:~/dataset$ cp testing.123 testing.456
student@debian:~/dataset$ ls -i
6553 one.txt 7437 testing.123 7438 testing.456 7427 two.txt
|
In the example above using the cp command what happens with the inodes for testing.123 and test.456 - are they the same?
Syntax:
cp [-i] <file1> <file2>
|
How would you copy the file testing.456 into your home directory - using partial pathnames?
Once you've made a copy of the file, check the new file's inode. Is it different to the original?
What would the inode number be if you had moved the file instead of copying it?
You can delete files with the "rm" (short for remove) command.
student@debian:~/dataset$ ls one.txt testing.123 two.txt student@debian:~/dataset$ rm testing.123 student@debian:~/dataset$ ls one.txt two.txt testing.456 student@debian:~/dataset$ |
You can use the "-r" flag with "rm" to recursively delete files and directories. Use this option with extreme caution!
Syntax: rm [-ir] <filename> |
Delete the previous "testing.456" file that we created with touch, and then copied and/or moved into your home directory.
To create and remove directories, you can use the mkdir (make directory) and rmdir (remove directory) commands:
student@debian:~/dataset$ ls
one.txt two.txt
student@debian:~/dataset$ mkdir testdir
student@debian:~/dataset$ cd testdir
student@debian:~/dataset/testdir$ ls
student@debian:~/dataset/testdir$ cd ..
student@debian:~/dataset$ rmdir testdir
student@debian:~/dataset$ ls
one.txt two.txt
|
Create a directory called "test". Now try the following command inside your "dataset" directory:
cp one.txt test
What happens to test? Does it become overwritten with "one.txt"? Or does something else happen?
This is a very powerful command and we will only cover the basics here.
The "grep" command will search through a file for a certain pattern, and then display lines, which contain the matching pattern:
student@debian:~/dataset$ grep "action" one.txt
Jefri complained about missing all the action, but Johanna
|
You don't have to put the search pattern in double quotation marks, but it does help to avoid confusion, especially with more complicated patterns, so it's a good habit to get into.
You can also use grep on an input stream; see the pipe ("|") section further on in the course.
The command also has the following flags:
-n displays the line numbers of the lines which match -v inverts the match, ie, displays non-matching lines -i makes the match case-insensitive |
student@debian:~/dataset$ grep "action" one.txt
Jefri complained about missing all the action, but Johanna
student@debian:~/dataset$ grep -vi "action" one.txt
The coldsleep itself was dreamless. Three days ago they had
been getting ready to leave, and now they were here. Little
Olsndot was glad she&apos;d been asleep; she had known some of
the grownups on the other ship.
-- A Fire Upon the Deep, Vernor Vinge (pg 11)
student@debian:~/dataset$ _
|
Syntax:
grep [-nvi] <filename1> <filename...>
|
Practice using the grep command using the switches above. Can you find all the lines in the file called "two.txt" which contain a the letter "l".
The find command is powerful, but is sometimes tricky to get ones head around.
Syntax:
find from-directory [-options matchspec] [and-action]
From-directory:
/ to specify a directory name
. current directory
|
Remember though that you would have to have permissions to look in the directory(ies) that you specify to search through.
Options and matchspec:
name "foo.txt"
This option matches all file names matching the pattern, wildcards such as "*" and "?" can be used, but then the name should be enclosed in quotes
type f, d, c, b, l, s, etc.
Matches all files of a certain type, e.g. f=regular file, d=directory file, c=character device file, b=block device file, etcetera
user username
Matches all files belonging to the specified user
group groupname
Matches all the files belonging to a certain group
You could negate an option using the exclamation mark ("!"), but check first on escaping the meaning of certain characters to the shell (especially the bash shell).
And-action:
To print the results to the terminal screen; this is the default action.
exec command {} \;
If finding a match, then execute the command on that file. The Syntax for this is important, the curly braces will hold the name of the file that has been found in order that the command can execute. The semicolon means separate the commands so if there is more than one match found each will be dealt with. The backslash escapes the meaning of the semicolon to the shell and keeps it as a semicolon.
ok command {} \;
If finding a match, then ask if it is OK to execute the command on that file. The Syntax for this is important, the curly braces will hold the name of the file that has been found in order that the command can execute. The semicolon means separate the commands so if there is more than one match found each will be dealt with. The backslash escapes the meaning of the semicolon to the shell and keeps it as a semicolon.
student@debian:~$ find . -name "one.txt"
./dataset/one.txt
student@debian:~$ find . -name "one.txt" -ok rm {} \;
< rm ... ./dataset/one.txt > ? n
student@debian:~$ find . -name "one.txt" -exec cat {} \;
The coldsleep itself was dreamless. Three days ago they had
been getting ready to leave, and now they were here. Little
Jefri complained about missing all the action, but Johanna
Olsndot was glad she&apos;d been asleep; she had known some of
the grownups on the other ship.
-- A Fire Upon the Deep, Vernor Vinge (pg 11) |
Let's just analyse the second example to see exactly what happens:
It does find the file, we know that from our first example.
Now it has to execute a command on that file:
-ok rm {foo.txt};
Do not remove this file so say NO when it asks Y/N? to removing that file, and enter.
If there had been two files with the name found (foo.txt and tmp/foo.txt) then each would have been put into the same command sequence as follows:
-ok rm {foo.txt}; -ok rm {tmp/foo.txt};
Each time you would have been asked if you wanted to remove the file and each time you would give your answer Y/N and enter.
student@debian:~$ find dataset -name "*.txt" -exec ls -l {} \;
-rw-r--r-- 1 student student 321 Feb 19 03:10 dataset/one.txt
-rw-r--r-- 1 student student 150 Feb 19 03:45 dataset/two.txt
|
This command does a long listing on all files in the "dataset" directory which end in ".txt"
student@debian:~$ find . \! -name "*.txt"
.
./.bashrc
./.bash_profile
./.bash_history
./dataset
./dataset2
./dataset2/relay01.dat
./dataset2/relay02.dat
./dataset2/relay03.dat
|
You can also use the "-o" option to cause the options to be logically ordered:
student@debian:~$ find . -name "one.*" -o -name "two.*"
./dataset/one.txt
./dataset/two.txt
|
As you can see, this finds all files in the current directory which begin in either "one." OR "two.".
student@debian:~$ find . -name "*.txt" -user student foo.txt |
The head and tail commands can be used to inspect the first 10 or the last 10 lines of a file, respectively. You can specify a "-#" parameter to change the number of lines that are displayed.
student@debian:~/dataset$ head /etc/passwd root:x:0:0:root:/root:/bin/bash daemon:x:1:1:daemon:/usr/sbin:/bin/sh bin:x:2:2:bin:/bin:/bin/sh sys:x:3:3:sys:/dev:/bin/sh sync:x:4:100:sync:/bin:/bin/sync games:x:5:100:games:/usr/games:/bin/sh man:x:6:100:man:/var/cache/man:/bin/sh lp:x:7:7:lp:/var/spool/lpd:/bin/sh mail:x:8:8:mail:/var/mail:/bin/sh news:x:9:9:news:/var/spool/news:/bin/sh student@debian:~/dataset$ head one.txt The coldsleep itself was dreamless. Three days ago they had been getting ready to leave, and now they were here. Little Jefri complained about missing all the action, but Johanna Olsndot was glad she&apos;d been asleep; she had known some of the grownups on the other ship. -- A Fire Upon the Deep, Vernor Vinge (pg 11) student@debian:~/dataset$ _ |
Syntax: head [-#] <file1> <file#> tail [-#] <file1> <file#> |
Can you head or tail more than one file using a single command? How?
The "wc" or word count command does a word count on a file, and displays the following information:
lines, words, characters
You can also use the -l, -w and -c switches to limit the command to only displaying some of these.
student@debian:~/dataset$ wc one.txt
8 57 321 one.txt
student@debian:~/dataset$ wc -l one.txt
8 one.txt
student@debian:~/dataset$ _
|
Syntax:
wc [-lwc] <file> <file1>
l -- displays lines in file
w -- displays words in file
c -- displays characters in file
|
Can you run wc on more than one file at once? Can you combine the commands switches?
The "gzip" command can be used to reduce the size of a file using adaptive Lempel-Ziv, while "bzip2" uses the Burrows-Wheeler block sorting text compression algorithm together with Huffman coding.[28]
"gzip" is the most popular compression utility on the Linux platform; files compressed with it end in a ".gz" extension - it tends to give better compression that "compress".
"bzip2" is more recent, and requires more memory to compress a file, but usually gives a better compression ratio than "gzip".
student@debian:~/dataset$ ls -l one*
-rw-r--r-- 1 student student 321 Feb 19 03:10 one.txt
student@debian:~/dataset$ gzip one.txt
student@debian:~/dataset$ ls -l one*
-rw-r--r-- 1 student student 247 Feb 19 03:10 one.txt.gz
student@debian:~/dataset$
|
You'll note that the command automatically renames the file to ".gz" and that the file size has decreased.
The commands each have a related command, which is the same name, but prefixed with an "un"- to reverse the process:
student@debian:~/dataset$ ls -l one* -rw-r--r-- 1 student student 247 Feb 19 03:10 one.txt.gz student@debian:~/dataset$ gunzip one.txt.gz student@debian:~/dataset$ ls -l one* -rw-r--r-- 1 student student 321 Feb 19 03:10 one.txt |
Syntax:
gzip <file>
gunzip <file.gz>
|
A wildcard is a pattern-matching character. It is useful in the following ways:
An asterisk (*) will match zero, one or more characters.
A question mark will match any single character (?)
Putting options into square brackets means either-or e.g. [ab] either an "a" or a "b"
To use the square brackets with a dash option means a range e.g. [0-9] a single character of any of the range 0 through to 9 (0,1,2,3,4,5,6,7,8 or 9)
If wanting to select a range within the alphabet e.g. [a-z] would mean a single character that might match any of the letters in the entire lowercase alphabet.
Could use the brackets to specify letters and numbers as follows: [a-e1-5] would match a single character that is either a letter in the range a to e or numerical 1 to 5. (a,b,c,d,e,1,2,3,4 or 5)
Using a bang at the beginning of the expression in the square brackets would negate the expression. [!ab] meaning a single character that is not an "a" or a "b".
Another interesting variation would be the following: [1-57] which would mean any single character in the range of numbers 1 through 5 or the number 7. (1,2,3,4,5 or 7)
Here's how you long list all the files in your "dataset2" directory ending with .txt:
student@debian:~/dataset2$ ls -l *.txt |
Here's how you list all the files starting with o and ending with xt:
student@debian:~/dataset2$ ls o*txt -rw-r--r-- 1 student student 0 feb 19 04:59 org.txt |
The following command will copy all files starting with "b" through to "f" and ending with anything (*) from your dataset2 directory to your previous dataset directory. The [b-f] option indicates one single digit or character.
student@debian:~/dataset2$ cp [b-f]* /tmp/
student@debian:~/dataset2$
|
If you have the following files in your directory:
foot
foo2
foo.txt
filer
file
files
greper
grep202
fast
slower
peanuts100
12.bed
camping.tent
|
These files are not in your directories, it is a rhetorical question only - question yourself as to what will happen in each of these examples before just accepting the answer as a given:
rm file* Which files will be removed?
filer
files
file (an asterisk means zero characters as well)
cp foo* tmp Which files will be copied?
foot
foo2
foo.txt
mv f[a-z]?.*] tmp Which files will be moved?
foo.txt
|
Starts with a "f" then a single character of lowercase alphabet,any single character with the "?", then a full-stop, then zero one or more characters.
cp [!ft] tmp
greper
grep202
slower
peanuts100
12.bed
camping.tent
Any file name that does not have an "f" or a "t" in it.
cp [!f][l-z]??[1-5][0-9][1-5] tmp/
grep202
|
The filename starts with any single character except an "f", then a single character between "l" and "z" (l,m,n,o,p,q,r,s,t,u,v,w,x,y or z), then two single characters (any characters), then a number between 1 and 5, then a number between 0 and 9, the last character is again a number between 1 and 5.
Ok, now that you've worked out the answers above using just your head, use the "touch" command to actually create the files, and perform the commands on them. Do the actual results match those you had worked out?
Unix filesystems (including BSD's UFS and Linux's ext2fs, ext3fs and XFS) support file links. Links are used to have one or more copies of a file in many places at once, without duplicating the actual data of the file for each copy. This is often used to save space, or to help when moving data from one location in the filesystem to another.
Each link points to the original copy of the file; the way in which the link points to a file determines whether the link is a "hard" link or a "soft" link, also known as a "symbolic" link.
Hard links are created with the "ln" command:
student@debian:~/dataset$ ls -li total 8 1101067 -rw-r--r-- 1 student student 321 Feb 19 03:10 one.txt 1101076 -rw-r--r-- 1 student student 150 Feb 19 03:45 two.txt student@debian:~/dataset$ ln one.txt chapterone.txt student@debian:~/dataset$ ls -li total 12 1101067 -rw-r--r-- 2 student student 321 Feb 19 03:10 chapterone.txt 1101067 -rw-r--r-- 2 student student 321 Feb 19 03:10 one.txt 1101076 -rw-r--r-- 1 student student 150 Feb 19 03:45 two.txt student@debian:~/dataset$ _ |
You'll notice that the inode number for both files are the same; this is how hard links work. The actual contents of the file, its data blocks, have not been duplicated, merely its directory entry.
You'll see that if you edit one file, the other file's contents are also changed.
Hard links share an inode, and therefore they can only be created on the same filesystem where the original file exists.
Removing a file, which is a hard link doesn't delete the file it only removes the link. The file itself is only removed once all the filesystem link entries that point to it are removed.
Then the inode becomes a shadow inode and is zero-ised in the directory listing. [29]
student@debian:~/dataset$ ls -li
total 12
1101067 -rw-r--r-- 2 student student 321 Feb 19 03:10 chapterone.txt
1101067 -rw-r--r-- 2 student student 321 Feb 19 03:10 one.txt
1101076 -rw-r--r-- 1 student student 150 Feb 19 03:45 two.txt
student@debian:~/dataset$ rm one.txt
student@debian:~/dataset$ ls -li
total 8
1101067 -rw-r--r-- 1 student student 321 Feb 19 03:10 chapterone.txt
1101076 -rw-r--r-- 1 student student 150 Feb 19 03:45 two.txt
|
In the example above, we've deleted the original file, but you can see that the actual contents are still preserved, as we still have another directory entry for the same inode number.
Now use "cp" to make a backup copy of "chapterone.txt", and then delete it. Now use "ls" to check what's changed with the inode numbers. Change "chapterone.txt" back to "one.txt" when you're finished.
A symbolic link is a pointer to another file path; you use "ln" in conjunction with the "-s" switch to create a symbolic link:
student@debian:~/dataset$ ls -il
total 8
1101067 -rw-r--r-- 1 student student 321 Feb 19 03:10 one.txt
1101076 -rw-r--r-- 1 student student 150 Feb 19 03:45 two.txt
student@debian:~/dataset$ ln -s two.txt chaptertwo.txt
student@debian:~/dataset$ ls -il
total 8
1101075 lrwxrwxrwx 1 student student 7 Feb 19 05:08
chaptertwo.txt -> two.txt
1101067 -rw-r--r-- 1 student student 321 Feb 19 03:10 one.txt
1101076 -rw-r--r-- 1 student student 150 Feb 19 03:45 two.txt
|
Symbolic links can traverse different filesystems, and so are often useful when shuffling data off a full disk onto a new one, while still preserving the directory path to the original file.
You'll notice that a symbolic link is given it's own inode number, unlike hard links, which share another filename's inode number.
An example of when you'd use this in real life: you have a big database in "/home/database", and you want to move it onto a partition mounted on "/scratch" which has a lot more free space. The problem is that the database software has been configured to use "/home/database" to access its files.
What you can do is stop the database, move the "database" directory out of "/home" and into "/scratch", and then set a symbolic link called "database" in "/home" to point to the real "database" directory in "/scratch".
Now when you restart your database, it will still be able to find its files where it expects them!
[28] See http://www.data-compression.com/lempelziv.html for an explanation on how the Lempel-Ziv encoding algorithm works, very interesting.
[29] You could see this if piping a directory listing that you know has shadow inodes through a hex dump tool.
|
|
 |
|
| The Shell Command Interpreter |  |
File permissions/security |