| Chapter 4. The Kernel versus Process Management | ||
|---|---|---|

|
 |
|
| Chapter 4. The Kernel versus Process Management | ||
|---|---|---|
|
|
|
|
Table of Contents
We have logged in and we have access to the system, either as root or as a user.
In order to continue we need to get more familiar with the workings of the kernel in relation to the operating system, the user and the hardware.
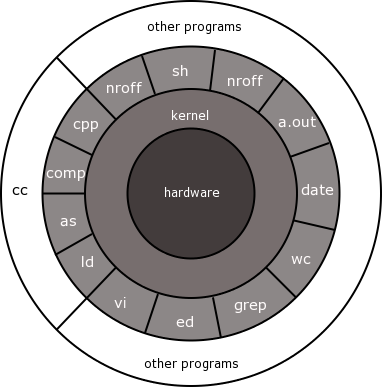
Let's look at the diagram that we used in the Fundamentals course explaining the layered structure and workings of the operating system. We also used a version of this diagram before in chapter 3.
![[Note]](../images/admon/note.png) |
Note |
|---|---|
|
We have covered the important part of the hardware knowledge required here in the "history" section above - please re-read if unsure as understanding of that level is important. |
|
Remember that the kernel controls:
System call facility that allows processes to use kernel functions.
Process creation and tracking
Process priority control
Swapping pages
IPC - inter-process communication
Cache, Buffer and I/O management
File creation, removal and modification and permissions
Multiple filesystems
Log file data accumulation
So the kernel itself is a process manager, what does that mean to the user running a command in the Applications layer and wanting a result immediately displayed on the terminal screen.
Executing a program in userland or user-mode does not mean that the program can access the kernel in any way. If the program is executed in kernel mode there are no restrictions to the kernel.
We have already discussed how each CPU has its own instruction set to switch from User to Kernel modes and then to return from kernel to user mode.
A user executing a request will only need to access kernel mode if the requested service is a kernel provided service. It accesses the kernel service through something called a system call (mentioned in Fundamentals course)
A user wants to access a regular file or a directory file, the user is issuing a command (Application Layer or Standard Library of Utilities Layer), but in order to get the information required the hard disk is going to have to be accessed, and the hard disk is defined as a block device. Therefore it has a block device file in /dev and has to be accesses through the kernel.
PREVIOUS EXPLANATION (Fundamentals): "The procedures in the Standard Library are called, and these procedures ensure that a trap instruction switches from User mode into Kernel mode and that the kernel then gets the control to perform the work requested of it."
Let's look at some of the relevant system calls (Standard Library of Procedures) that would have to take place: switch()
switch () -- A switch has to be made from user to kernel mode - switch() is a TRAP written in C in order to be able to talk to the assembler code needed to talk to the hardware device. switch() is a system call.
open() --Now the file has to be opened, as a process could not access a file in any other way. The system call, open(), is structured as follows:
fd = open(path, flag, mode)
|
where:
fd= a file descriptor and an open file object are created, the file descriptor links the process and the opened file and the object contains the relevant data for the link such as a pointer to the kernel memory being used, a current position or offset from where the next function that has to be performed on that file, where the file actually is, and even a pointer to the other functions specified by the flag field defined below.
path= the pathname of where the file is to be found
flag= how the file must be opened, or if it must be created (read, write, append)
mode= access rights of newly created file
flock() -- As more than one user could be accessing the same file there is an flock() system call which allows file operation synchronisation on the entire file or just parts of the file.
creat() -- If the file does not exist it will need to be created and this is the function name for that system call. (Handled the same as open() by the kernel.)
read() write() -- Device files are usually accessed sequentially (regular files either randomly or sequentially.) From the current pointer or offset a read() or write() can be performed. Nread/nwrite specifies the number of characters read /written and updates the offset value.
lseek(), close(), rename() and unlink() -- To change the value of the offset the kernel will use lseek().
close(fd) -- To close a file the syntax would be close(fd) using the file descriptor name
rename(old,new) -- To rename = rename(old, new)
unlink() -- To remove = unlink(pathname) this one may make more sense a little later in this course, but this will change the parent directory count and list.
PREVIOUS EXPLANATION (Fundamentals): "Once the kernel has performed the task, it will return a successful or a failure status and then instigates a return from the trap instruction back into user mode. exit()
In the case of the exit() system call we would hope that the brackets would contain a zero (0) to represent a successful completion of a process.
|
|
 |
|
| Terminal Emulation |  |
Process Management |