| Process Management | ||
|---|---|---|

|
Chapter 4. The Kernel versus Process Management |  |
| Process Management | ||
|---|---|---|
|
|
Chapter 4. The Kernel versus Process Management | |
A program is an executable file on the hard disk, whereas a process is a running program.
A process is an instance of a disk program in memory, executing instructions on the processor.
The only way to run a program on a Unix/Linux system is to request the kernel to execute it via an exec() system call.
Remember that the only things that can make system calls are processes (binary programs that are executing.)
So how do you as a human get the kernel to run a program for you? The shell acts as your gateway to the kernel! You use the shell to make system calls to the kernel on your behalf in fact, the shell is simply an interface for you to get access to the kernel's exec() system call.
When you type in a command line to the shell, the shell parses your input in a certain way. Let's take a look at how the shell does this, say you type in a few arbitrary words as follows:
$ one space three four
|
The shell will parse this line into separate fields where each field is separated by an IFS or Internal Field Separator character, which is by default set to whitespace (any combination of spaces and/or tabs.)
Refer to the next diagram.
In a simple command line (no pipes) the shell will regard the first field as the name of a command to run.[2]
All the remaining fields are seen as command line arguments to pass to that command. The shell determines whether it knows the command as a built-in, or an external program on the disk, as found in the first matching directory in the PATH variable.
If the command is a shell built-in, the shell just runs a function within its existing program in memory, with the same name as the built-in command, and passes the arguments from the command line as arguments to the function.
If the command is an external program on the disk (binary or shell script,) the shell will perform an exec() system call, and specify the path to the program and the command line arguments, in the parenthesis of the exec() system call. For example if you type the following command at the shell prompt
$ ls -al
|
the shell will run code similar to the following:
execle("/bin/ls", "ls", "-al", "TERM=linux,LOGNAME=joe, ")
|
As you can see the shell has simply given you access to the kernels exec() system call.
The creation of a process, through the exec() system call, is always performed through an existing process. The kernel keeps track of which process created another. You can use "ps" to show the kernels process table, or excerpts thereof, to determine a process' process ID (PID) and parent process ID (PPID.)
If you run the following command
linux:/ # ps -f
UID PID PPID C STIME TTY TIME CMD
root 4421 4411 0 15:49 pts/7 00:00:00 su
root 4422 4421 0 15:49 pts/7 00:00:00 bash
root 4429 4422 0 15:50 pts/7 00:00:00 ps -f
|
You will see all the processes started in your current login session. This is just a small excerpt from the kernels entire process table. Look at the PPID column of the ps command that you ran above. Can you see that the PPID of ps is the same as the PID of your shell process (we'll assume "bash")?
Now make a note of that shell's PPID. Let's try and find its parent (I assuming that you are in your login shell and that you have not started any sub-shells by hand.) Now run the following command:
$ ps -ef | less
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 1 0 0 75 0 - 155 schedu ? 00:00:04 init
0 S 0 2 1 0 75 0 - 0 contex ? 00:00:00 keventd
0 S 0 3 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd_CPU0
0 S 0 4 1 0 85 0 - 0 kswapd ? 00:00:00 kswapd
0 S 0 5 1 0 85 0 - 0 bdflus ? 00:00:00 bdflush
0 S 0 6 1 0 75 0 - 0 schedu ? 00:00:00 kupdated
0 S 0 7 1 0 85 0 - 0 kinode ? 00:00:00 kinoded
0 S 0 8 1 0 85 0 - 0 md_thr ? 00:00:00 mdrecoveryd
0 S 0 11 1 0 75 0 - 0 schedu ? 00:00:00 kreiserfsd
0 S 0 386 1 0 60 -20 - 0 down_i ? 00:00:00 lvm-mpd
0 S 0 899 1 0 75 0 - 390 schedu ? 00:00:00 syslogd
0 S 0 902 1 0 75 0 - 593 syslog ? 00:00:00 klogd
|
Look in the PID column for the same number that you saw in your shell's PPID column. The process that you find will be the parent of your shell. What is it? It is the login program. Using the same methodology as before now find Login's parent. It is "init". Now find "init's" parent. Can you see that "init" has no parent in the process table?
Who or what started "init", the kernel!
Remember that "init" is the first process run by the kernel at bootup: this behaviour is hard-coded in the kernel. It is "init's" job to start up various child processes to get the system to a usable state (Refer to bootup section Refer to init section.)
What constitutes a process or the properties of a process?
A process consists of:
An entry in the process table
Data area, etcetera uarea (contains the properties of the process)
The properties of a process
A process has many status properties maintained by the kernel, some of which are:
RUID: Numeric real (login) user ID
RGID: Numeric real (login) group ID
EUID: Numeric effective user ID
EGID: Numeric effictive group ID
PID: Numeric proces ID
PPID: Numeric parent process ID
When a process is started it inherits most of the properties of its parent, such as the real and effective UID/GID values.
Every process also has an environment associated with it. The environment is simply a list of variables. These are passed to a process by it's parent process, when it makes the exec() system call.
Every UNIX kernel has one or more forms of the exec() system call. Although we generally refer to "exec()", the exact call names may differ slightly, but they all start with "exec".
On Linux, the kernel's variant of the traditional exec() system call is called execve(2), and its syntax is:
execve(program_file, program_arguements, environment_variables)
|
The standard C library on Linux provides several different interfaces to the low-level execvp() system call, all providing slightly different behaviour. These library calls are:
execl(3)
execlp(3)
execle(3)
execv(3)
execvp(3)
To see the difference between these calls, you can look up the man pages for them in the relevant manual sections.
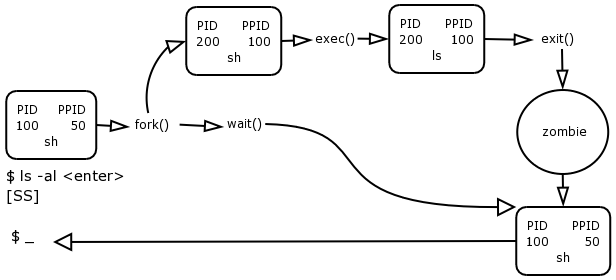
Although the basic way to run a process is through exec(), the whole process creation effort is a bit more involved. When a C programmer wants to start a process there are a few more system calls that will usually be used together with exec(). To better explain this we will look at a process creation example, namely that of running an "ls" command from the shell.
When you type in "ls -a" the shell does the following:
As you hit enter after the "ls -al" command, the shell determines that ls is an external program on the filesystem, namely /bin/ls. It needs to exec() this. What it does first is to issue a fork() system call. It then issues a wait() system call.
The fork() system call performs a type of cloning operation. This gets the kernel to copy an existing process table entry to a next empty slot in the process table.
This effectively creates a template for a new process.
The kernel now assigns a new unique PID to this forked process and updates its PPID to reflect the value of the process that forked it. The forker is called the parent process and the forked process is called the child process.
The parent process, in this case the shell, now issues the exec() system call on behalf of the child. The exec() system call gets the kernel to read the ls program off the filesystem on the hard disk and place it into memory, overwriting the calling process, in this case the child shell template.
The PID and PPID entries of the forked child remain the same, but the name of the child process in the process table entry is now updated to the name of the exceed process, in this case ls.
The child now runs and in the case of "ls -al", produces some output to the terminal. Once the child is finished whatever it has to do it informs the kernel that it has completed by issuing an exit() system call.
The wait() causes the parent to halt execution until the child performs its' exit().
The exiting child now falls into a "zombie"* state. The kernel has de-allocated the process memory, however its process table entry still exists. It is the job of the parent to inform the kernel that it has finished working with the child, and that the kernel can now remove the process table entry from the child (currently in the zombie state)[3]
The exit() of the child actually causes the return of the wait() system call, which ends the pausing of the parent process, so that it can now continue running.
It is important to note that every process becomes zombie for a brief amount of time when it exits, usually a split second, as a part of its natural life cycle.
What would happen if shell omitted the wait()?
You would get the shell prompt back, the child process would continue to run until completed and if the parent shell still exists it will still receive the exit status from the child process and would still have the task of informing the kernel that the child process is complete. So that the kernel can remove the child's entry from the process table.
To show the state of a process, use the "-l" to the ps command.
Example
$ ps -el
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
0 S 0 1 0 0 75 0 - 155 schedu ? 00:00:04 init
0 S 0 2 1 0 75 0 - 0 contex ? 00:00:00 keventd
0 S 0 3 1 0 94 19 - 0 ksofti ? 00:00:00 ksoftirqd_CPU0
0 S 0 4 1 0 85 0 - 0 kswapd ? 00:00:00 kswapd
0 S 0 5 1 0 85 0 - 0 bdflus ? 00:00:00 bdflush
0 S 0 6 1 0 75 0 - 0 schedu ? 00:00:00 kupdated
0 S 0 7 1 0 85 0 - 0 kinode ? 00:00:00 kinoded
0 S 0 8 1 0 85 0 - 0 md_thr ? 00:00:00 mdrecoveryd
0 S 0 11 1 0 75 0 - 0 schedu ? 00:00:00 kreiserfsd
0 S 0 386 1 0 60 -20 - 0 down_i ? 00:00:00 lvm-mpd
0 S 0 899 1 0 75 0 - 390 schedu ? 00:00:00 syslogd
|
Look for the column heading "S" (it is the second column)
| symbol | meaning |
|---|---|
| S | sleeping |
| R | running |
| D | waiting (usually for IO) |
| T | stopped (suspended) or traced |
| Z | zombie (defunct) |
The scheduler is a service provided by the kernel to manage processes and the fair distribution of CPU time between them.
The scheduler is implemented as a set of functions in the kernel. On Unix System V**, the scheduler is represented in the process table as a process named sched, with a PID of 0. Linux does not indicate the scheduler in this way. Even on system V this serves no practical purpose as not even the root user can manipulate the scheduler by sending it signals with the kill command.[4]
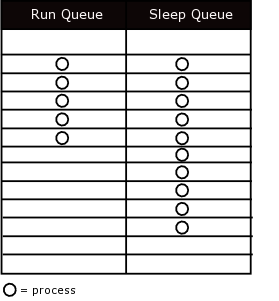
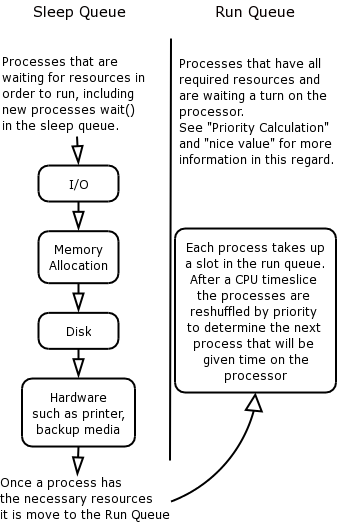
The kernel classifies processes as being in one of two possible queues at any given time: the sleep queue and the run queue.
Processes in the run queue compete for access to the CPU. If you have more processes that want to execute instructions than you have processors in your system, then it becomes obvious that you have to share this finite resource between these processes.
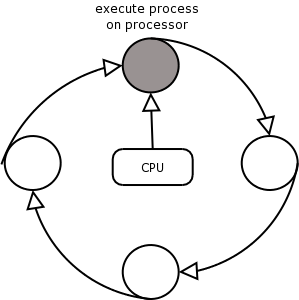
The processes in the run queue compete for the processor(s). It is the schedulers' job to allocate a time slice to each process, and to let each process run on the processor for a certain amount of time in turn.
Each time slice is so short (fractions of a second), and each process in the run queue gets to run often every second it appears as though all of these processes are "running at the same time". This is called round robin scheduling.
As you can see, on a uniprocessor system, only one process can ever execute instructions at any one time. Only on a multiprocessor system can true multiprocessing occur, with more than one process (as many as there are CPUs) executing instructions simultaneously.
There are different classes of scheduling besides round-robin. An example would be real-time scheduling, beyond the scope of this course.
Different Unix systems have different scheduling classes and features, and Linux is no exception.
Find out which different scheduling classes and features are supported by different Unix flavours including Linux.
Look up some information about a distribution of Linux called RTLinux (Real Time Linux).
Processes that are waiting for a resource to become available wait on the sleep queue in this way, the process will not take up a slot on the run queue and during the priority calculation.
However once the resource becomes available that resource is reserved by that process, which is then moved back onto the run queue to wait for a turn on the processor.
If we look at this in a different way we will find that every process gets onto the sleep queue, even as a new process the resources still have to be allocated to the process, even if the resource is readily available.
[2] There are three main types of command:Shell built-ins, Binary programs, Shell programs/scripts Refer to the Shell Scripting course for more information.
[3] A zombie process is also known as a defunct process.
[4] This includes SVR3 systems like Open Server 5, SVR4 systems like Solaris and SVR5 systems like UnixWare 7.
|
|
 |
|
| Chapter 4. The Kernel versus Process Management |  |
Linux Multitasking |