| Generic Unix filesystem enhancements | ||
|---|---|---|

|
Chapter 8. Tips and Tricks |  |
| Generic Unix filesystem enhancements | ||
|---|---|---|
|
|
Chapter 8. Tips and Tricks | |
Various enhancements were made to the original Unix filesystem by different people. These enhancements are:
Free blocks bitmap
Block groups
Extents
Datablock pre-allocation
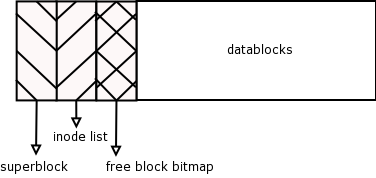
The free blocks bitmap contains a one-to-one status map of which data blocks contain data. One bit describes one data file, a one in the bitmap indicates the corresponding datablock is in use and a zero indicates that it is free.
This was originally a BSD extension to UFS, made by UCB in the BSD FAST FILESYSTEM (FFS). What was done for for FFS (the Berkeley "Fast File System") was to have a "free blocks bitmap" for each cylinder group.
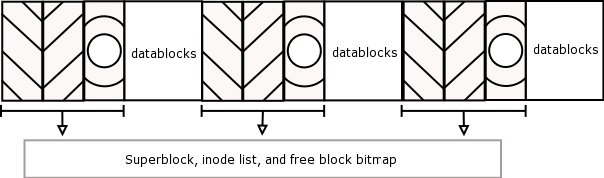
To make disk access faster, the filesystem can be divided into block groups, a block group simply contains all the part of the filesystem that a generic Unix filesystem is made of as shown in Figure 5. However, the distributing of multiple superblocks inodes and data block areas around the entire physical disk allows the system to allocate an inode closer to its data blocks.
This means that when a new file is saved, the system will find some free blocks to allocate for data and then try to find a free inode that is in the nearest inode list before the data blocks that were allocated.
In contrast, for example, on a 1GIG filesystem of the traditional Unix type (as in Figure 5), reading a file whose data blocks were near the end of the filesystem, would result in the heads on the disk moving a far distance to the beginning of the filesystem to read the inode for that file. If this filesystem utilised block groups, then the inode for this file would be much closer to the end of the filesystem and to the data blocks, so the heads would have a comparatively shorter distance to travel.
Extent based allocation is an efficiency improvement to the way that disk block addresses are referenced in the inode.
Instead of referencing each and every data block number in the inode, contiguous block addresses can simply be referenced as a range of blocks. This saves space for large files that have many data blocks.
For example if a file takes up data blocks 21, 22, 23, 24 and 25, expressing this as a block range in an extent based filesystem would specify 21-25 instead.
To prevent micro-fragmentation of data blocks, of a single file, all around the filesystem, the filesystem driver can pre-allocate data blocks in entire groups at a time.
For instance, if a file is first saved, that consumes 3 blocks, 32 blocks (if this were the pre-allocation size for this specific filesystem) would be allocated for this file in one go. The remaining 29 blocks would not be sued for other files. When this file grows, the new blocks can therefore be allocated contiguously after the first three.
Pre-allocation is handled transparently by the filesystem driver behind the scenes. This means that although fragmentation still occurs as a natural part of a filesystem structure, file data is stored in large ranges of blocks, so that single blocks of a file are never scattered individually around the filesystem.
The blocks pre-allocated in this scheme will not show as allocated in the output of df, and will immediately be sacrificed automatically when disk space runs low.
|
|
 |
|
| General Information on hard disk partitions |  |
Filesystems |