| Filesystems | ||
|---|---|---|

|
Chapter 8. Tips and Tricks |  |
| Filesystems | ||
|---|---|---|
|
|
Chapter 8. Tips and Tricks | |
I would like to take you through some general information on filesystems before going into the specific types available with Linux.
We did look at filesystems and inodes, and the installation in the system adminsitration course, and then we did a bootup section in this course. Each time we spoke about the system mounting the root filesystem before the booting process can complete.
You can have more than one filesystem on your system, why would you want to do that though?
A smaller filesystem is easier to control and easier to maintain.
Smaller filesystems or divisions are quicker as the searching for datablocks is over a smaller area on disk. So if you have an active system the size of your filesystems will affect performance.
Backups can become easier as some filesystems do not change that much and do not need such a rigid backup routine as other sections that are changing all the time.
Put different operations onto different sections, for example, the development area is separate from the financial records and the user area where data capture goes on all the time.
Security is enhanced as a sensitive area need only be accessible at certain times (mounted) and secured at other times (not mounted).
Organises the disk space within a division.
Manages files and implements file types (regular, directory, device etcetera.)
Maps filenames to the inodes
Maps file offsets to logical block numbers (watches for bad tracks as well)
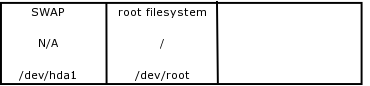
A filesystem is an area of blocks allocated on the disk. See Figure 1 (Hard Disk Partitions). These are logical divisions on the Linux partition.
A logical decision must be made to ascertain how big each area should be, take into account the number of users you have and the amount of data you will need. As it is fairly difficult to re-allocate space on a working system please put some thought into this.
Where:
S=swap space allocated 64MB
Root filesystem allocated 800MB
Development filesystem allocated 300MB
Data Capturing filesystem allocated 1500MB
During the installation you specified that your first logical partition was hda1 and that it was 64MB, this is an extention of virtual memory the system creates a device file that points to that area on the disk from block x to block y (Minor device number) and that the type of filesystem is a swap space (major device number). This filesystem is not accessed by the user and therefore is not mounted or attached.
The root filesystem is created by block p to block t and is 800 MB in size. During the bootup process, the kernel and the drivers work together and the root structure (/dev/hda2) is mounted or attached to the mount point (/).
Through this mounting process the user can now see the directory hierarchy and the entire system that has installed within the root filesystem.
If you did not attached the datablocks referenced by /dev/hda2 to a mount point you would not be able to see the operating system.
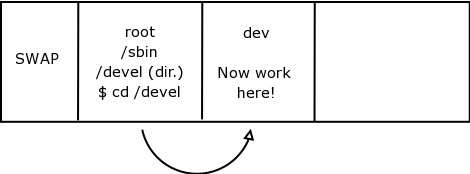
# mount /dev/devel /devel
|
When you created the development filesystem, you called it devel, the kernel then created a related device file called /dev/devel or /dev/hda3, this device file points to a set of datablocks that are 300 MB in size.
You will be asked where you want to mount this filesystem and let's say we decide to call the mountpoint /devel. An empty directory called devel is created directly under /.
When you attach the device file to the mount point, it is no longer an empty directory but a pointer to a set of datablocks, so when you change directory into /devel you actually move to the relevant data block section of the disk. (refer to Figure 8 - Where are you working now?)
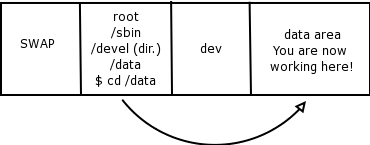
# mount /dev/data /data
|
Again you choose to create a filesystem called /dev/data or /dev/hda4. Once mounted or attached it represents a set of datablocks pointed to by the major and minor device numbers of that device.[8]
At the beginning of this course we spoke of mounting different versions or types of filesystems, those that are not of Linux type.
Some of these filesystems would have to have some kernel support built in to the Linux kernel.
Some would have utilities to work with them, even if not mounted and without kernel support being required.
To do this you would work with programs that require user space only.
mtools: for MSDOS filesystem (MS-DOS, Windows)
dosfstools for MS-DOS FAT filesystem
cpmtools: for CP-M filesystem
hfsutils: for HFS filesystem (native Macintosh)
hfsplus: for HFS+ filesystem (modern Macintosh)
When you create a filesystem of say 800MB the system also creates a superblock, and inode table and then the datablock allocation for that filesystem.
Inode numbers start at 1 although 1 is never allocated out, inode number 2 usually points to the root directory file. They are stored as a sequential array at the front of the filesystem and that structure is called the ilist, inode table or inode list.
The amount of inodes required for each filesystem is calculated depending on the data block size of the filesystem. (Generally works at approx 4K per inode).
Each inode is 64 bytes in size and we have already covered in the Fundamentals course the fields contained therein.
The disk inodes are the ones residing on the hard disk and not in the buffer cache and normally defined in ino.h header file.
The maximum size of an ext2 filesystem is 4 TB, while the maximum file size is currently limited to 2 GB by the Linux kernel.
Disk block addressing is controlled by the inode and the field that expresses the actual datablocks that contains the physical file, the address field is a total of 39 bytes in length.
Although most files are fairly small, the maximum file size in Linux is 2GB, how does the inode cope with addressing that number of disk blocks?
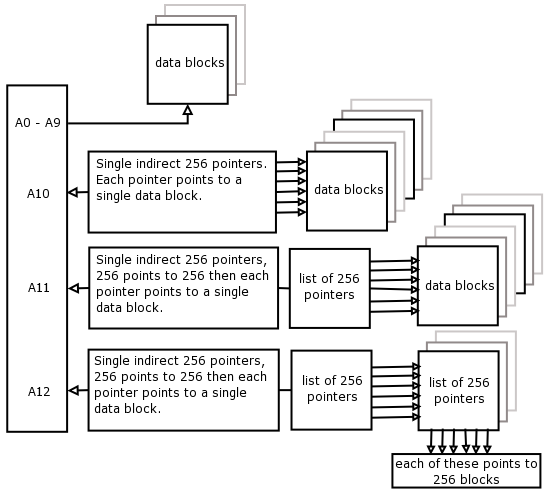
The inode block numbers work in a group of 13:
The first 10 point directly to a datablock which contain the actual file data - this is called direct addressing = 10Kb.
Then the 11th block points to a datablock that contains 256 pointers, each of those pointers point to a single address block as above. This is called single indirect block addressing = 256Kb.
The 12th block points to a datablock that has 256 pointers and each of those pointers point to a datablock with 256 pointers, and each of those pointers to a datablock as per point 1 above. This is called double indirect block addressing = 64Mb.
The 13th point has a triple indirect setup where the 256 pointers each point to 256 pointers that each point to 256 pointers that each point to a datablock as per point 1 above = 16GB.
So the max size is actually 16GB, BUT this is limited by the inode sizing not by the structure of the operating system.
In memory, inodes are managed in two ways:
1. A doubly linked circular list and,
2. A hash table.
Function iget(struct super_block *sb, int nr) to get the inode, if it is already in memory, then I_count is incremented, if it is not found, must select a "free" inode call superblock function read_inode(0 to fill it, then add it to the list.
(See Iput(), namei())
Let's take a step backwards and look at the function, locality and general information on the superblock itself.
Each filesystem or logical allocation of blocks on the hard disk physical Linux partition will have a superblock and an inode table.
When the filesystem is mounted or attached to a mount point, a switch on the superblock is marked as open and the superblock is put into memory.
If for any reason the filesystem is unattached in an unorthodox manner, e.g. a system crash, switching off the machine etcetera then this switch is still set to open and the filesystem is then considered dirty.
When you attempt to remount this filesystem you will have to run a process to clean up the superblock where it attempts to match the "picture" of the filesystem on harddisk to the superblock picture in memory before it can successfully mount the filesystem the pictures have to be the same.
Quite often we hear of people who run the fix-up program (used to be called fsck) and answer the questions to delete, move, reallocate blocks and they answer as best they can.
The best way is to let the fix-it program run on its own and do its best to make things right. We will look at this program later on in this section.
The Superblock contains a description of the basic size and shape of this file system. The information within it allows the file system manager to use and maintain the file system.
To quote from the man pages:
Amongst other information it holds the: Magic Number This allows the mounting software to check that this is indeed the Superblock for an EXT2 file system. For the current version of EXT2 this is 0xEF53. Revision Level The major and minor revision levels allow the mounting code to determine whether or not this file system supports features that are only available in particular revisions of the file system. There are also feature compatibility fields which help the mounting code to determine which new features can safely be used on this file system, Mount Count and Maximum Mount Count Together these allow the system to determine if the file system should be fully checked. The mount count is incremented each time the file system is mounted and when it equals the maximum mount count the warning message "maximal mount count reached, running e2fsck is recommended" is displayed, Block Group Number The Block Group number that holds this copy of the Superblock, Block Size The size of the block for this file system in bytes, for example 1024 bytes, Blocks per Group The number of blocks in a group. Like the block size this is fixed when the file system is created, Free Blocks The number of free blocks in the file system, Free Inodes The number of free Inodes in the file system, First Inode This is the inode number of the first inode in the file system. The first inode in an EXT2 root file system would be the directory entry for the '/' directory.
Usually only the Superblock in Block Group 0 is read when the file system is mounted but each Block Group contains a duplicate copy in case of file system corruption.
EXT2 file system tries to overcome fragmentation problem by allocating the new blocks for a file physically close to its current data blocks or at least in the same Block Group as its current data blocks.
Blocks Bitmap
Inode Bitmap
Inode Table
Free blocks count
Free Inodes count
Used directory count
We have spoken before as to how the buffer cache can improve the speed of access to the underlying devices.
This buffer cache is independent of the file systems and is integrated into the mechanisms that the Linux kernel uses to allocate and read and write data buffers.
All block structured devices register themselves with the Linux kernel and present a uniform, block based, usually asynchronous interface.
Linux uses the bdflush kernel daemon to perform a lot of housekeeping duties on the cache.
Some of these functions would happen automatically as a result of the cache being used. Please remember that this report could differ from version to version.
bdflush version ?.?
0: 60 Max fraction of LRU list to examine for dirty blocks
1: 500 Max number of dirty blocks to write each time bdflush activated
2: 64 Num of clean buffers to be loaded onto free list by refill_freelist
3: 256 Dirty block threshold for activating bdflush in refill_freelist
4: 15 Percentage of cache to scan for free clusters
5: 3000 Time for data buffers to age before flushing
6: 500 Time for non-data (dir, bitmap, etc) buffers to age before flushing
7: 1884 Time buffer cache load average constant
8: 2 LAV ratio.
|
If you flush the buffers often, it is more efficient if you have a system crash because everything would have been updated from the buffers to the disk - HOWEVER if you do this too often you will see a degrade on performance.
Work to have a balance here as well, flush the buffers often enough to be safe for your system. If your system is very active maybe you need to flush more often. If you have a development environment then flush less often (less activity in the buffers).
We used to average 30 seconds and then work on the performance from that point.
[8] hda4 is the last primary logical division that comes as a default standard. If you need further filesystems you will have to create logical partitions.
|
|
 |
|
| Generic Unix filesystem enhancements |  |
The Virtual Filesystem |